![Beer Hold [BOFH]Basilisk's Blog!](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjQS53pOwZRWg6Y83Yt48g23r_BmYAdM4rNBksZTxNf2eLYgMEztBGgUN6WXPwSYROnYSmo3IW8txRZ3BayDTNVU8BVrfdSXYQlDvVWe4Y3sDnPtZpNLTedZ9bAk8lCHRIQSuN8/s1600-r/bofh.gif)
This post is one of a number of reviews of the Eclipse Ganymede release. It has been added to the Ganymede Around the World map. Donate and become a Friend of Eclipse!
One of the projects that is part of the Ganymede simultaneous release is the Eclipse Communication Framework (ECF). I had never done anything with it before, so writing a review is a great chance to actually do something with it. The update site for getting is ECF is:
http://download.eclipse.org/technology/ecf/2.0/3.4/updateSite/site.xml
One of the things you will get is a communication perspective. In this perspective, you have the following two buttons, the first one for connecting to an IM provider, the second one for connecting to a collaboration server. In this review I will focus on the XMPP connectivity available under the "Connect to Provider" button. XMPP is the protocol used by Jabber and GTalk, and I happen to have two GTalk users (one is for XMPP testing purposes for some components I made using the Smack API).

The "Connect to Provider" and "Connect Workspace to Collaboration Group" buttons
To connect to e.g. GTalk or another Jabber server, select the XMPP provider. This requires you to enter your user name, the XMPP server and the port number where the XMPP server resides. In the case of GTalk you will only have to enter username@gmail.com. It will then connect to the default port 5222 and authenticate with the given user name.
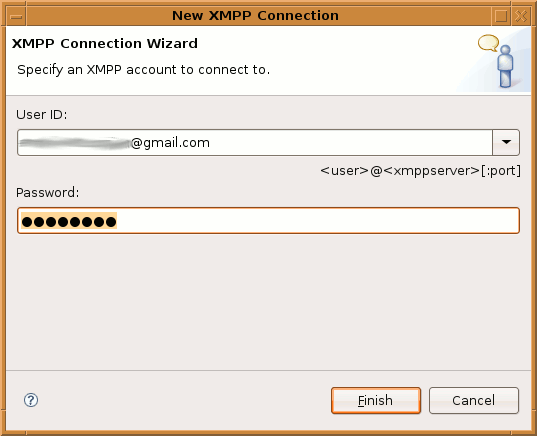
The "New XMPP Connection" dialog where you can enter the XMPP connection string
Once connected, you will see the the contacts view appear with the list of your GTalk buddies. Double click a buddy and you can happily start chatting from within Eclipse. One of the drawbacks that I see here is the fact that you must be in the communication perspective (or add the communication buttons to your Java perspective). The communication views themselves do not provide buttons for connecting and are just a gray area with some explanatory text. This is something that could be done better I think. I would expect a list of accounts and the ability to add accounts via a context menu in a view, much like the server view of the JEE tooling.
GTalk buddies in the contacts view
There is also no way of automatically connecting (see bug 181510), requiring me to continuously go through these steps in order to connect. Furthermore, the XMPP connect dialog only allows user@host for both the user name (used for authentication) and the server name. I can foresee problems here, as with Jabber/ XMPP the domain used for authentication is not necessarily the server name you connect to.
You can collaborate with your Jabber/ GTalk buddies via XMPP. You can send URL's, screen captures, files, etc. from within the contacts view by right clicking a buddy. Sending URL's via XMPP requires the receiver's permission before it is opened, which is a good thing in case a malicious user were to send out links to malicious websites. When using the ECF collaboration server, there are no such controls in place, causing the web site to immediately appear in the receiving Eclipse.
To share an editor via XMPP, right click in the editor, select "Share Editor With" and navigate to a buddy. The receiver is now asked permission and upon acceptance the shared editor is opened. Changes in one editor are propagated to the other. The following screen cast shows the simultaneous update of the two editors in action (or click here if it does not display):
Click the play button to see a screen cast of the two shared editors being updated in sync
Conclusion
ECF looks promising when using the XMPP provider. It allows you to use your existing IM accounts in Eclipse and provides collaboration features such as shared editors. This comes in handy for distributed teams or in case you deal with home workers (like I do). The ability to connect to your existing buddies and get all these collaboration features inside the IDE is nice.
Now for the bad: The way things are presented is IMO not the best and could use quite a bit of rework. It is usable, just not very user friendly yet. The way XMPP user names and server names are entered might cause problems for some Jabber installs, e.g. in case you have "username@some.group" as user ID and the server name is "myjabberserver.com". ECF uses the Smack API for XMPP connectivity, and that API does not support HTTP proxies yet (a request that is outstanding for quite some time now). This will require you to do some tunneling in case you are behind a firewall. Receiving screen captures does not require permission from the receiver.
Some of these issues are minor, some are not. There is a lot of room for improvement. The project has sparked my interest though, and I will follow its progress and hope to see those improvements in future releases.